
트리 알고리즘
5-1 결정 트리
주제: 결정트리를 이용한 와인 분류
목차
1. 로지스틱 회귀를 이용한 와인 분류
2. 결정 트리란?
3. 결정 트리를 이용한 와인 분류
로지스틱 회귀를 이용한 와인 분류
# 데이터 수집
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine-date')
# 데이터 정보 알아보기
wine.head()
head 메서드를 이용하면 처음 5개의 샘플을 확인할 수 있습니다.
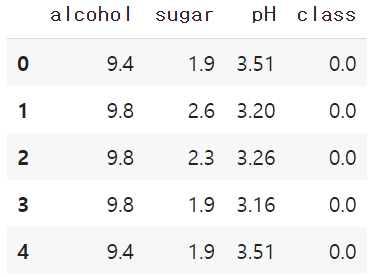
표를 통해서 특성값에는 알코올 도수, 당도, ph가 있으며 이진 분류 문제라는 것을 알 수 있습니다.
# 데이터 정보 알아보기
wine.info()
info 메서드를 이용하면 데이터프레임의 각 열의 데이터 타입과 누락된 데이터가 존재하는지 알려줍니다.

해당 출력 결과를 통하여 6497개의 샘플이 존재하며 모든 열의 데이터 타입이 실수라는 것을 알 수 있습니다.
# 데이터 정보 알아보기
wine.describe()
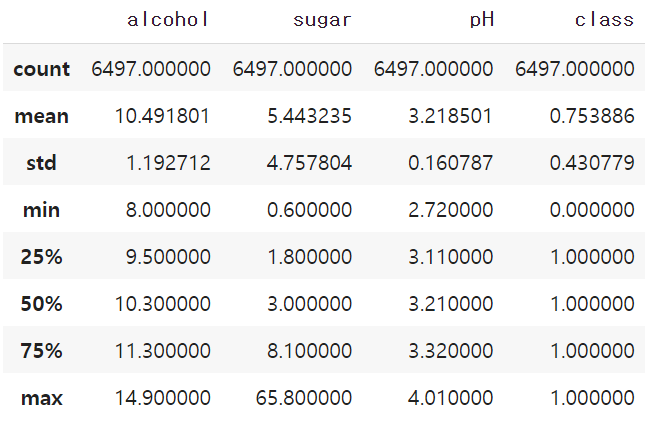
describe 메서드는 열에 대한 간략한 통계를 출력해 줍니다.
최소, 최대, 평균값 드엥 관한 정보를 얻을 수 있습니다.
# 데이터 전처리 및 학습
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state = 42) # test_size는 테스트 데이터의 비율을 정해줌
# 정규화
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
# 학습
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
# 출력 결과
0.7808350971714451
0.7776923076923077
출력 결과를 통해 로지스틱 회귀 모델은 와인의 분류에 어려움이 있다는 것을 알 수 있습니다.
결정 트리란?
결정 트리의 구조는 자식 노드와 부모 노드로 이루어져 있습니다.
부모 노드에서 특성에 대한 조건을 제시하며 조건에 따라 좌우의 노드로 이동하게 됩니다.
결정 트리를 이용한 와인 분류
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
# 출력 결과
0.996921300750433
0.8592307692307692
해당 출력 결과를 통해 모델이 과대 적합된 것을 알 수 있습니다.
해당 모델의 결과가 어떤 구조를 거쳐 나왔는지 확인하기 위해 트리 구조를 살펴 봅시다.
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()
이렇게 보면 구체적인 정보를 얻기 어렵기 때문에 트리의 깊이를 제한해서 출력해 보도록 하겠습니다.
plot_tree(dt, max_depth=1, filled=True, feature_names = ['alcohol', 'sugar', 'pH'])
# max_depth는 트리의 깊이를 제한, filled는 클래스마다 색상을 부여해줌
plt.show()
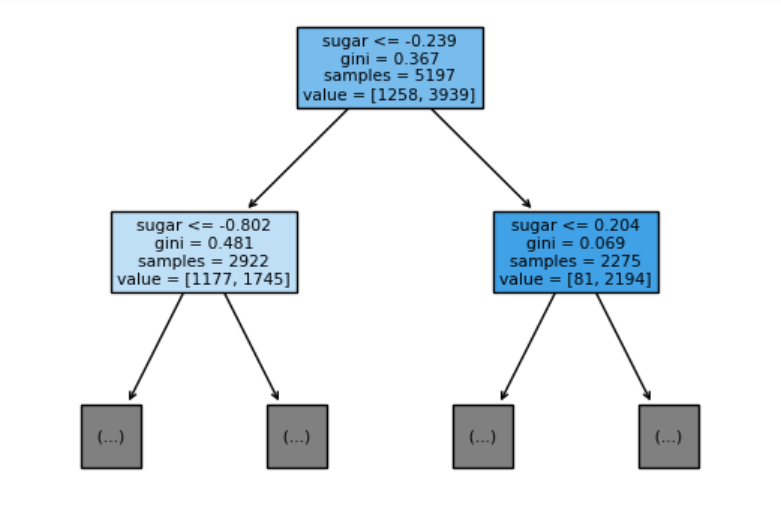
해당 그림의 박스 내부에는 위에서 부터 4개의 정보가 존재합니다.
첫번째 정보는 테스트의 조건을 의미합니다.
두번째 정보는 불순도를 의미합니다.
세번째 정보는 총 샘플의 수를 의미합니다.
네번째 정보는 클래스 별 샘플의 수를 의미합니다.
결정 트리에서 예측을 하는 방법은 리프 노드에서 가장 많은 클래스가 예측 클래스가 됩니다.
불순도란?
불순도의 역할은 해당 모델의 critrion 매개변수의 값으로 노드에서 데이터를 분할할 기준을 정합니다.
gini는 지니 불순도를 의미합니다.
지니 불순도를 구하는 수식은 1 - (음성 클래스 비율 ** 2 + 양성 클래스 비율 ** 2)가 됩니다.
결정 트리 모델은 부모 노드와 자식 노드의 불순도 차이를 가능한 크도록 설계합니다.
이러한 불순도의 차이를 정보 이득이라고 칭합니다.
현재 모델이 과대 적합되었는데, 이 문제를 해결하기 위해 트리의 깊이를 제한해 보도록 하겠습니다.
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
# 출력 결과
0.8454877814123533
0.8415384615384616
훈련 세트의 성능은 낮아졌지만 테스트 세트의 성능은 거의 그대로입니다.
해당 모델을 트리 그래프를 통해 알아봅시다.
plt.figure(figsize = (10,7))
plot_tree(dt, filled=True, feature_names = ['alcohol', 'sugar', 'pH'])
plt.show()
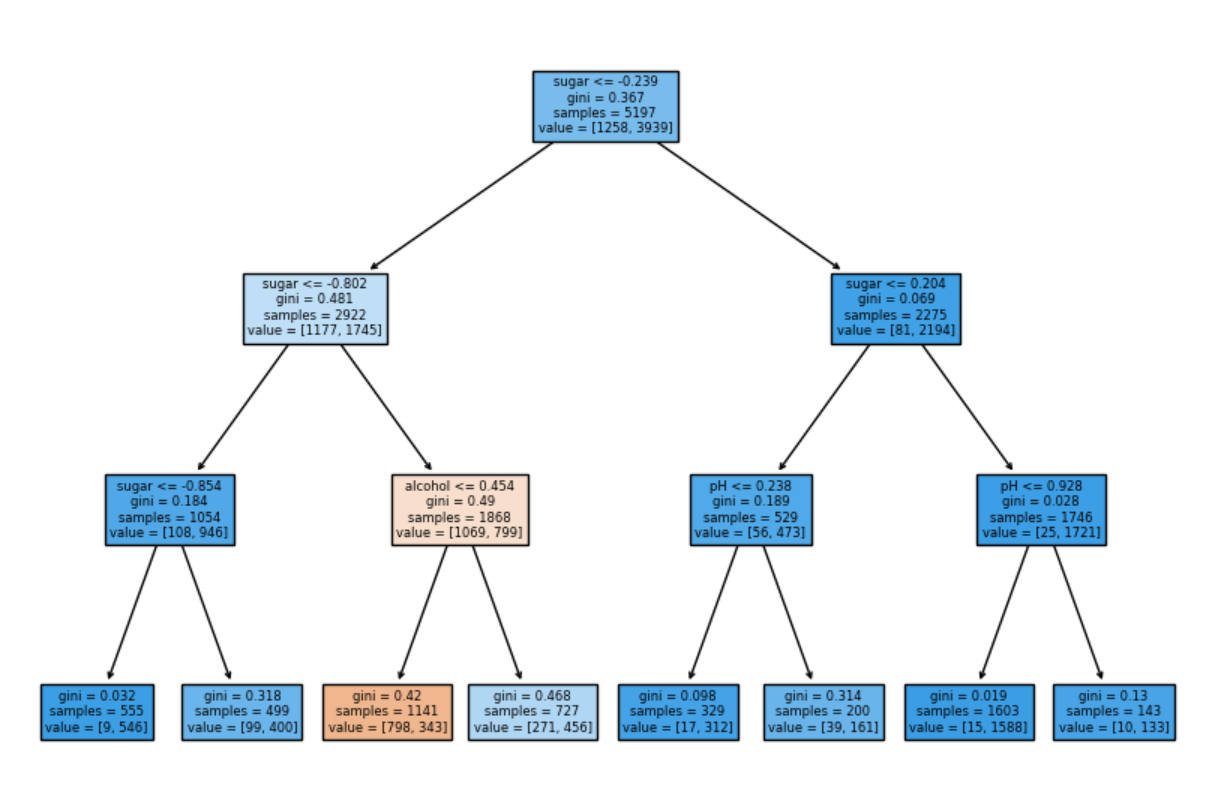
여기서 특성의 수치가 모두 표준화되어 이해하기가 약간 어렵습니다.
하지만 결정 트리 모델은 표준화를 할 필요가 없습니다.
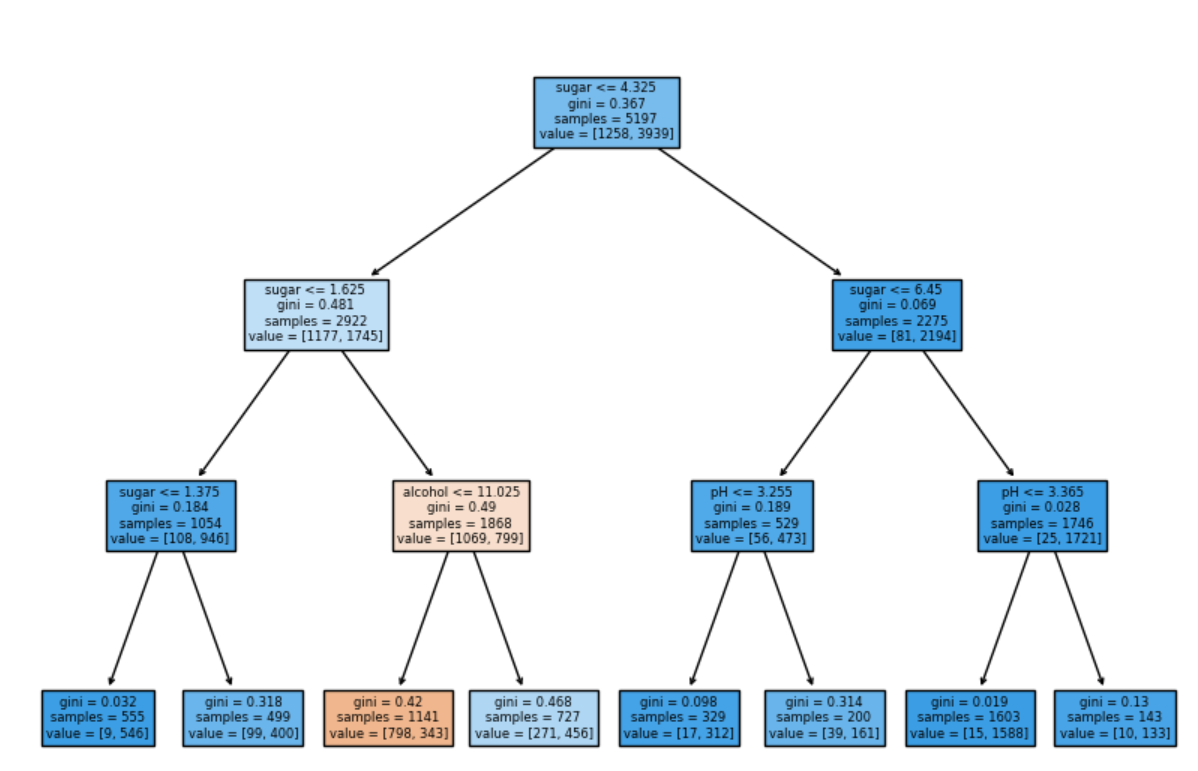
표준화를 진행하지 않으니 특성의 수치를 이해하기 쉬워졌습니다.
마지막으로 결정 트리가 어떤 특성을 가장 유용하다고 판단했는지 알아보겠습니다.
print(dt.feature_importances_)
# 출력 결과
[0.12345626 0.86862934 0.0079144 ]
트리에서 자주 등장했던 특성인 당도가 가장 높게 나온 것을 알 수 있습니다.
결정 트리의 또 다른 특징은 결정 트리의 특성 중요도를 특성 선택에 활용할 수 있다는 것입니다.
5-2 교차 검증과 그리드 서치
주제: 검증 세트의 필요 이유 및 그리드 서치
목차
1. 검증 세트
2. 교차 검증
3. 그리드 서치
4. 랜덤 서치
검증 세트란?
지금까지의 훈련은 훈련 세트를 이용해 학습 후 테스트 세트를 사용해 성능을 확인 했습니다.
하지만 테스트 세트를 사용해 자꾸 성능을 확인하다 보면 점점 테스트 세트에 모델이 맞춰집니다.
따라서 검증 세트를 도입해 모델 제작 후 마지막에 딱 한 번만 사용하는 것이 좋습니다.
검증 세트를 만들기 위해서는 훈련세트와, 테스트 세트로 데이터를 나누고 해당 테스트 세트를 또 나누면 됩니다.
sub_input, val_input, sub_target, val_target = train_test_split(data, target, test_size = 0.2, random_state = 42)
이제 검증 모델까지 사용하여 모델을 만들고 평가해 보겠습니다.
dt.fit(sub_input, sub_target)
print(dt.score(sub_input, sub_target))
print(dt.score(val_input, val_target))
# 출력 결과
0.997113302862641
0.864423076923077
따라서 해당 모델이 훈련 세트에 과대적합된 것을 알 수 있습니다.
교차 검증
교차 검증이란 검증 세트를 떼어 내어 평가하는 과정을 여러번 반복합니다.
그 후 이 점수를 평균해 최종 점수를 얻습니다.
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)
import numpy as np
print(np.mean(scores['test_score']))
# 출력 결과
{'fit_time': array([0.00738001, 0.00705671, 0.0052259 , 0.00869322, 0.00625062]), 'score_time': array([0.00163579, 0.00177288, 0.00188231, 0.00180173, 0.00169706]), 'test_score': array([0.84230769, 0.83365385, 0.84504331, 0.8373436 , 0.8479307 ])}
0.8412558303102096
score 변수에는 모델의 훈련 시간, 검증 시간, 점수가 담겨있습니다.
해당 점수들을 모두 평균을 내어 구하면 최하단의 결과가 나오는 것을 볼 수 있습니다.
하지만 cross_validate는 훈련 세트를 섞어 폴드를 나누지 않습니다.
따라서 분할기를 사용하여 훈련 세트를 섞어야 합니다.
from sklearn.model_selection import StratifiedKFold
scores = cross_validate(dt, train_input, train_target, cv = StratifiedKFold())
print(np.mean(scores['test_score']))
만약 폴드의 수를 늘리고 싶다면 다음과 같이 하면 됩니다.
splitter = StratifiedKFold(n_splits = 10, shuffle=True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score']))
그리드 서치
머신러닝 모델에서 모델이 학습하지 못하고 사용자가 지정해주어야 하는 파라미터를 하이퍼 파라미터라고 합니다.
그리드 서치는 최적의 하이퍼 파라미터 값을 찾기위해 사용됩니다.
먼저 min_impurity_decrease 매개변수의 최적값을 찾아보겠습니다.
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]} # 구하고자 하는 하이퍼 파라미터
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs = -1)
gs.fit(train_input, train_target)
dt = gs.best_estimator_ # 최적의 하이퍼 파라미터 모델
print(dt.score(train_input, train_target))
print(gs.best_params_) # 최적의 하이퍼 파라미터 값
print(gs.cv_results_['mean_test_score']) # 교차 검증의 평균 점수
best_index = np.argmax(gs.cv_results_['mean_test_score'])
print(gs.cv_results_['params'][best_index]) # 점수가 가장 높은 매개변수 탐색
# 출력 결과
0.9615162593804117
{'min_impurity_decrease': 0.0001}
[0.86819297 0.86453617 0.86492226 0.86780891 0.86761605]
{'min_impurity_decrease': 0.0001}
다음으로 여러 변수의 하이퍼 파라미터 값을 찾아보도록 하겠습니다.
params = {'min_impurity_decrease': np.arange(0.0001, 0.001, 0.0001),
'max_depth': range(5, 20, 1),
'min_samples_split': range(2, 100, 10)
}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs = -1)
gs.fit(train_input, train_target)
print(gs.best_params_)
print(np.max(gs.cv_results_['mean_test_score']))
# 출력 결과
{'max_depth': 14, 'min_impurity_decrease': 0.0004, 'min_samples_split': 12}
0.8683865773302731
하지만 위 과정에서는 아쉬운 점이 존재합니다.
앞에서 탐색할 매개변수의 간격을 0.0001 혹은 1로 설정했지만 이렇게 간격을 설정한 것에 대한 특별한 이유가 없습니다.
랜덤 서치
매개변수의 값이 수치일 때 값의 범위나 간격을 미리 정하기 어려울 수 있습니다.
또한 매개 변수 조건이 많다면 그리드 서치 수행 시간이 오래 걸릴 수 있습니다.
이럴 때는 랜덤 서치를 사용하면 좋습니다.
from scipy.stats import uniform, randint
rgen = randint(0, 10) # 0과 10 사이의 범위를 가짐
rgen.rvs(10) # 범위 내에서 10개의 샘플 추출
ugen = uniform(0, 1) # 0과 1사이의 범위를 가짐
ugen.rvs(10) # 범위 내에서 10개의 샘플 추출
# 출력 결과
array([9, 8, 0, 1, 0, 1, 5, 6, 2, 7])
array([0.53140428, 0.77112734, 0.11032664, 0.94618531, 0.99551544,
0.89359786, 0.23768084, 0.40227755, 0.50312295, 0.7748666 ])
이제 파라미터의 값을 랜덤으로 바꾸면서 랜덤서치를 진행해 보겠습니다.
params = {'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25)
}
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state = 42), params, n_iter = 100, n_jobs = -1, random_state = 42)
gs.fit(train_input, train_target)
print(gs.best_params_)
print(np.max(gs.cv_results_['mean_test_score']))
dt = gs.best_estimator_
print(dt.score(test_input, test_target))
# 출력 결과
{'max_depth': 39, 'min_impurity_decrease': 0.00034102546602601173, 'min_samples_leaf': 7, 'min_samples_split': 13}
0.8695428296438884
0.86
5-3 트리와 앙상블
주제: 앙상블 학습
목차
1. 정형 데이터와 비정형 데이터
2. 랜덤 포레스트
3. 엑스트라 트리
4. 그레디언트 부스팅
정형 데이터와 비정형 데이터
정형 데이터란 어떠한 구조로 되어 있는 데이터를 뜻합니다.
이러한 데이터는 csv나 데이터베이스에 저장하기 쉽습니다.
비정형 데이터란 텍스트 데이터, 이미지, 음악등이 존재합니다.
지금까지 학습한 알고리즘들은 모두 정형 데이터에 적합한 알고리즘이며 앙상블 학습은 정형 데이터를 다루는 학습에서 좋은 성과를 냅니다.
랜덤 포레스트란?
랜덤 포레스트는 앙상블 학습의 대표적인 모델입니다.
랜덤 포레스트는 결정 트리를 랜덤하게 만들어 하나의 숲을 만듭니다.
먼저 랜덤 포레스트의 각 트리는 부트스트랩 샘플을 이용해 훈련 데이터를 만듭니다.
부트스트랩 샘플이란?
데이터 세트에서 중복을 허용하여 데이터를 샘플링하는 방식
또한 노드 분할시 전체 특성 중에서 일부 특성을 무작위로 고른 다음 최선의 분할을 찾습니다.
정리하자면 랜덤 포레스트는 랜덤하게 선택한 샘플과 특성을 사용하기 때문에 훈련 세트에 과대적합되는 것을 막아주고 검증 세트와 테스트 세트에서 안정적인 성능을 얻을 수 있습니다.
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs = -1, random_state=42)
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs = -1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
# 출력 결과
0.9973541965122431 0.8905151032797809
랜덤 포레스트에는 자체적으로 모델을 평가하는 기능이 존재합니다.
랜덤 포레스트는 부트스트랩 샘플을 만들어 훈련을 진행하므로 남는 샘플이 존재합니다.
이러한 샘플을 oob 샘플이라 하며 검증 세트의 역할을 합니다.
rf = RandomForestClassifier(n_jobs = -1, random_state = 42, oob_score = True)
rf.fit(train_input, train_target)
print(rf.oob_score_)
엑스트라 트리란?
엑스트라 트리는 랜덤 포레스트와 매우 비슷하게 동작합니다.
하지만 부트스트랩 샘플을 사용하지 않는다는 차이점이 존재합니다.
대신 노드 분할 시 가장 좋은 분할을 찾지 않고 무작위로 분할합니다.
이는 결정 트리의 splitter 매개변수를 random으로 지정한 것과 같습니다.
하나의 결정 트리에서 특성을 무작위로 분할한다면 성능이 낮아지겠지만 많은 트리를 앙상블하기 때문에 과대적합을 막으며 검증 세트의 점수를 높입니다.
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs = -1, random_state=42)
scores = cross_validate(et, train_input, train_target, return_train_score=True, n_jobs = -1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
# 출력 결과
0.9974503966084433 0.8887848893166506
그레이디언트 부스팅
그레이디언트 부스팅은 깊이가 얕은 결정 트리를 사용하여 이전 트리의 오차를 보완하는 방식으로 앙상블 하는 방법입니다.
깊이가 얕은 결정 트리를 사용하기 때문에 높은 일반화 성능을 가집니다.
그레이디언트 부스팅은 결정 트리를 계속 추가하면서 오차가 가장 적은 방향으로 이동합니다.
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score = True, n_jobs = -1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
# 출력 결과
0.8881086892152563 0.8720430147331015
그레이디언트 부스팅에는 훈련 세트의 비율을 정할 수 있습니다.
하지만 비율이 1보다 작다면 경사 하강법의 단계마다 일부 샘플을 랜덤하게 선정하는 방식과 비슷합니다.
또한 그레이디언트 부스팅은 하나의 코어로만 연산이 가능해 속도가 느릴 수 있습니다.
이를 보완한 히스토그램 기반 그레이디언트 부스팅이 존재합니다.
히스토그램 기반 그레이디언트 부스팅은 입력 특성을 256개의 구간으로 나눕니다. 따라서 노드 분할 시 최적의 분할을 빠르게 찾을 수 있습니다.
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
hgb = HistGradientBoostingClassifier(random_state = 42)
scores = cross_validate(hgb, train_input, train_target, return_train_score = True)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
# 출력 결과
0.9321723946453317 0.8801241948619236
출력 결과를 보면 기본 그레이디언트 부스팅보다 조금 더 높은 성능을 제공하는 것을 알 수 있습니다.
또한 다양한 특성을 골고루 이용합니다.
추가적으로 XGBoost 라이브러리, LightGBM 라이브러리를 통하여 히스토그램 기반 그레이디언트 부스팅을 수행할 수 있습니다.
이상으로 포스팅을 마치겠습니다.