
k-최근접 이웃을 활용한 머신러닝
1-3 마켓과 머신러닝
주제: 두 종류의 생선을 분류하는 머신러닝
목차 1. 데이터 수집
2. 데이터 시각화
3. 머신러닝 모델 선정
4. 학습과 예측
5. knn모델에 관하여
데이터 수집
분류하고자하는 생선의 종류는 도미와 빙어가 있습니다.
다음은 도미와 빙어의 길이, 무게에 관한 데이터입니다.
#도미 데이터
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
#빙어 데이터
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
데이터 시각화
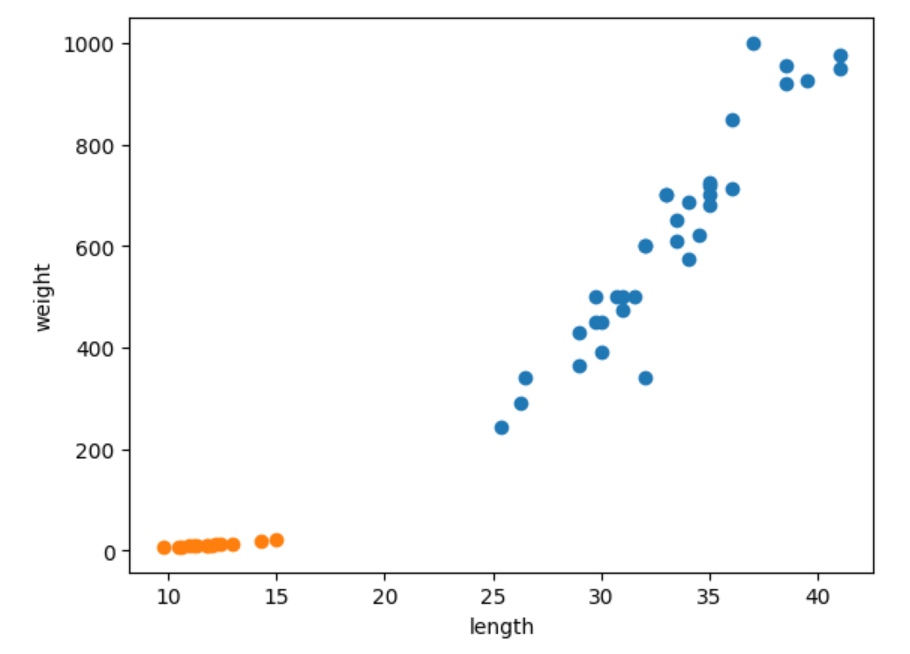
위 데이터의 특징을 수치만을 이용해서 알아내는 것은 어려우므로 파이썬의 라이브러리 matplotlib을 활용하여 시각화를 진행해봅시다.
다음은 시각화를 진행한 파이썬 코드와 산점도 그래프입니다.
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
머신러닝 모델 선정
데이터 시각화의 결과를 통해 파악 가능한 부분은 다음과 같습니다.
빙어(smelt)의 무게와 길이는 도미(bream)에 비해 매우 작다. 빙어(smelt)와 도미(bream)은 산점도상에서 특정 구역에 밀집되어있다.
위의 내용들을 종합해 보았을때 K-최근접 이웃 알고리즘을 사용한다면 도미와 빙어를 효율적으로 분류가 가능해 보입니다.
k-최근접 이웃 알고리즘이란?
새로운 입력으로 들어온 데이터를 특정값으로 분류하는데 현재 데이터와 가장 가까운 k개의 데이터를 찾아 가장 많은 분류 값으로 현재 데이터를 분류하는 알고리즘이다.
학습과 예측
사이킷런에서 제공해주는 knn을 사용하여 학습을 진행하겠습니다.
위 패키지를 이용하기 위해서는 데이터를 2차원으로 변환해야합니다.
다음은 1차원 데이터를 2차원 데이터로 합치는 과정입니다.
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
fish_data = [[l,w] for l, w in zip(length, weight)]
여기서 zip 함수란?
파라미터값에서 각각 하나씩 원소를 꺼내어 튜플로 반환하는 함수이다.
위 과정을 거치면 데이터는 다음과 같이 변환된다.
[[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0], [29.7, 450.0], [29.7, 500.0], [30.0, 390.0], [30.0, 450.0], [30.7, 500.0], [31.0, 475.0], [31.0, 500.0], [31.5, 500.0], [32.0, 340.0], [32.0, 600.0], [32.0, 600.0], [33.0, 700.0], [33.0, 700.0], [33.5, 610.0], [33.5, 650.0], [34.0, 575.0], [34.0, 685.0], [34.5, 620.0], [35.0, 680.0], [35.0, 700.0], [35.0, 725.0], [35.0, 720.0], [36.0, 714.0], [36.0, 850.0], [37.0, 1000.0], [38.5, 920.0], [38.5, 955.0], [39.5, 925.0], [41.0, 975.0], [41.0, 950.0], [9.8, 6.7], [10.5, 7.5], [10.6, 7.0], [11.0, 9.7], [11.2, 9.8], [11.3, 8.7], [11.8, 10.0], [11.8, 9.9], [12.0, 9.8], [12.2, 12.2], [12.4, 13.4], [13.0, 12.2], [14.3, 19.7], [15.0, 19.9]]
또한 각 데이터가 어떤 생선 데이터인지 알려주어야 하므로 도미는 1 빙어는 0으로 표현한 정답 데이터를 만듭니다.
fish_target = [1] * 35 + [0] * 14
이제 knn 모델을 임포트 하고 학습을 진행시킵시다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target)
kn.score(fish_data, fish_target)
kn.predict([[30,600]])
fit 메서드는 모델을 학습시키는 역할을 합니다.
input, target 값을 파라미터로 입력시 규칙을 학습합니다.
score 메서드는 모델의 훈련된 정도를 평가해주는 역할을 합니다.
훈련이 잘 되었다면 1을 리턴합니다.
predict 메서드는 새로운 데이터의 정답을 예측합니다.
현재 길이가 30, 무게가 600인 데이터를 입력했으므로 도미로 예측할 것입니다.
다음은 새로 추가된 데이터 [30,600]을 산점도 상에 표시하였습니다.
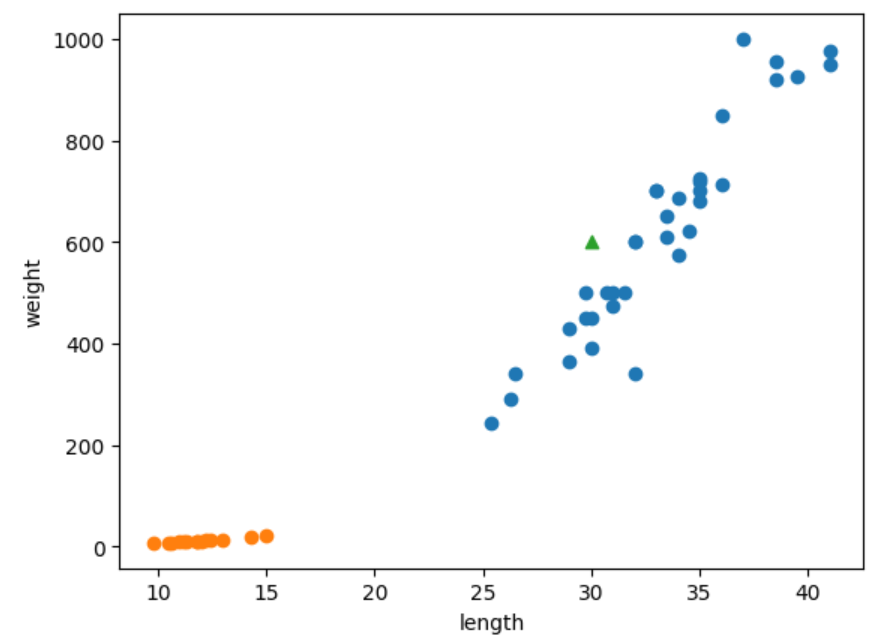
삼각형의 모양을 띄는 데이터가 새로 추가된 데이터이며 주변에는 도미 데이터가 대부분인 모습을 볼 수 있습니다.
따라서 knn 모델 또한 도미로 예측한 것을 알 수 있습니다.
knn모델에 관하여
knn모델은 가장 가까운 직선거리에 어떤 데이터가 있는지를 계산해야 하므로 데이터가 많은 경우에는 사용하기 어렵습니다. 또한 데이터가 크기 떄문에 메모리를 많이 사용합니다.
knn모델은 매게변수를 주어 참고 데이터의 계수를 변경할 수 있습니다.
따라서 훈련 데이터의 수에 맞추어 조절을 해주어야 합니다.
다음은 참고 데이터의 계수를 잘못 입력하였을때 일어날 수 있는 오류입니다.
kn49 = KNeighborsClassifier(n_neighbors= 49)
kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target)
이렇게 학습을 진행한다면 모든 데이터를 참고합니다. 하지만 49개의 데이터중에는 도미가 더 많으므로 무조건 도미로 예측하는 오류가 발생합니다.
knn 모델은 학습을 진행하는 것이 아닌 데이터를 참고하는 방식으로 예측을 합니다
2 데이터 다루기
목차 1. 지도 학습과 비지도 학습
2. 데이터 세트
3. 데이터 전처리
지도 학습과 비지도 학습
지도 학습이란 입력과 타겟을 이용하여 학습을 진행합니다.
이와 반대로 비지도 학습은 입력만을 이용해 스스로 특징을 파악하고 학습을 진행합니다.
이번 글에서 주로 사용되는 knn은 지도 학습을 이용합니다.
데이터 세트
머신러닝에서는 훈련을 위한 훈련 세트, 테스트를 위한 테스트 세트로 두개의 데이터 세트가 필요합니다.
다음은 훈련 세트와 테스트 세트를 만드는 과정입니다.
input_arr = fish_data[:35]
target_arr = fish_target[:35]
kn = kn.fit(input_arr, target_arr)
#fish_data, fish_target은 위에서 정의한 데이터와 같습니다
위와 같은 코드로 학습을 진행하게 되면 정확도는 0이 될 것입니다.
현재 훈련 데이터 35개는 모두 도미의 데이터이므로 빙어 데이터가 예측에서 주어진다면 판단할 수 없습니다.
이렇게 데이터 세트에 한 종류의 데이터가 편향되어 학습에 영향을 끼치는 것을 샘플링 편향이라 합니다.
이를 방지하기 위해 랜덤으로 데이터를 섞어서 슬라이싱하는 방법을 이용합니다.
다음은 넘파이 라이브러리를 이용하여 훈련 데이터를 만드는 코드입니다.
import numpy as np
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)
# np.array()를 활용하면 데이터를 보기 쉽게 행렬의 형태로 나타내 줍니다.
print(input_arr.shape)
#shape 메서드는 해당 행렬의 크기를 알려줍니다.
np.random.seed(42) # 랜덤 시드를 42로 설정합니다
index = np.arange(49) # 1~49 까지 숫자가 담긴 배열을 만듭니다
np.random.shuffle(index) # 위의 배열을 랜덤하게 셔플합니다
[13 45 47 44 17 27 26 25 31 19 12 4 34 8 3 6 40 41 46 15 9 16 24 33
30 0 43 32 5 29 11 36 1 21 2 37 35 23 39 10 22 18 48 20 7 42 14 28
38] # 이와 같은 배열이 만들어집니다
위 배열을 이용해 학습을 데이터 세트를 만듭시다.
train_input = input_arr[index[:35]] # 인덱스 배열의 34번째까지의 수에 해당하는 인덱스 값의 input_arr의 데이터를 순서대로 train_input에 저장합니다.
train_target = target_arr[index[:35]] # 인덱스 배열의 34번째까지의 수에 해당하는 인덱스 값의 target_arr의 데이터를 순서대로 train_target에 저장합니다.
test_input = input_arr[index[35:]]
test_target = target_arr[index[35:]]
plt.scatter(train_input[:,0], train_input[:,1]) # 첫번째 파라미터에는 2차원 데이터의 모든열의 1행의 정보를 입력
plt.scatter(test_input[:,0], test_input[:,1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
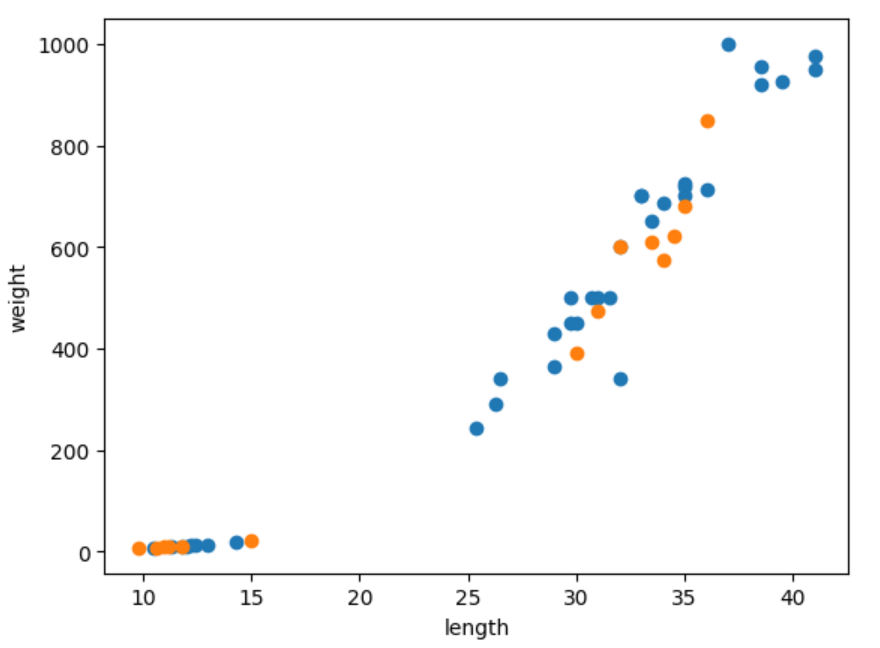
위 산점도에서 파란색으로 표시된 데이터는 훈련 데이터, 주황색으로 표시된 데이터는 테스트 데이터입니다.
다음 데이터를 이용해 학습을 진행하면 1의 정확도가 나옵니다.
데이터 전처리
라이브러리를 이용해 쉽게 전처리를 진행할 수 있습니다
#넘파이 라이브러리를 이용해 데이터 전처리 쉽게 하기
fish_data = np.column_stack((length,weight)) # column_stack은 1차원 데이터 두개를 합쳐 2차원 데이터로 만들어줍니다.
fish_target = np.concatenate((np.ones(35), np.zeros(14))) # concatenate는 단순하게 1차원 데이터 두개를 연결합니다.
#사이킷런으로 훈련 세트와 테스트 세트 나누기
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, random_state = 42, stratify=fish_target)
#랜덤하게 훈련 데이터와 테스트 데이터를 나눕니다.
#stratify=fish_target는 훈련 데이터와 테스트 데이터의 비율을 원본 데이터에서 도미와 빙어 데이터의 비율과 똑같이 맞추는것을 의미합니다.
#학습시키기
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
이렇게 학습을 진행하였습니다.
하지만 문제가 발생했습니다.
[25, 150]의 도미를 예측하라고 모델에게 입력하면 빙어로 예측합니다.
산점도를 이용해 문제를 파악해 봅시다.
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^') # 25,150 데이터를 삼각형으로 표시
plt.show()
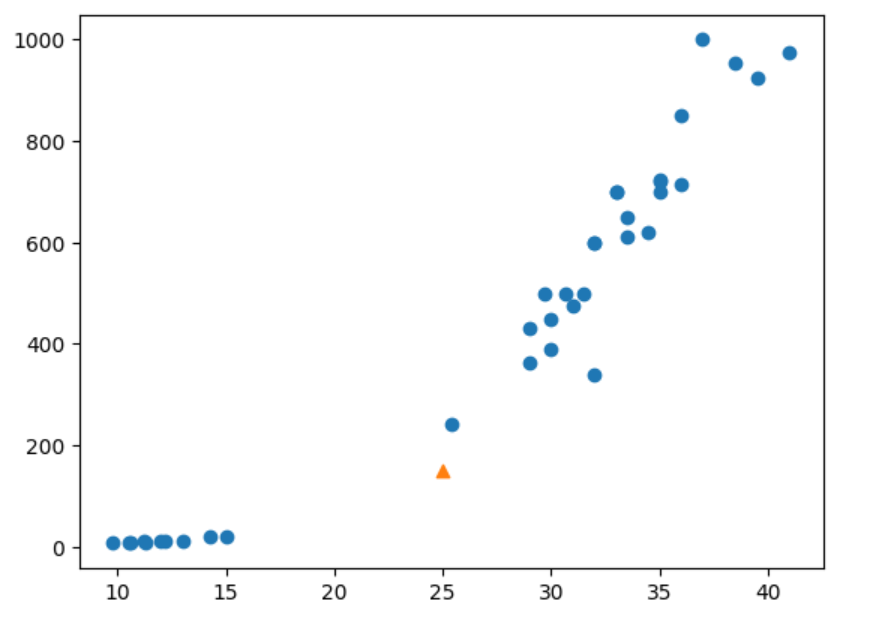
분명 해당 데이터는 도미와 더 가깝습니다.
knn 모델에게 해당 데이터 주변 5개의 데이터를 요청해 봅시다.
#근접하는 객체들의 정보 알아내기
distances, indexes = kn.kneighbors([[25,150]]) #25,150 주변 데이터에 대한 정보 추출
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^')
plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D')
plt.show()
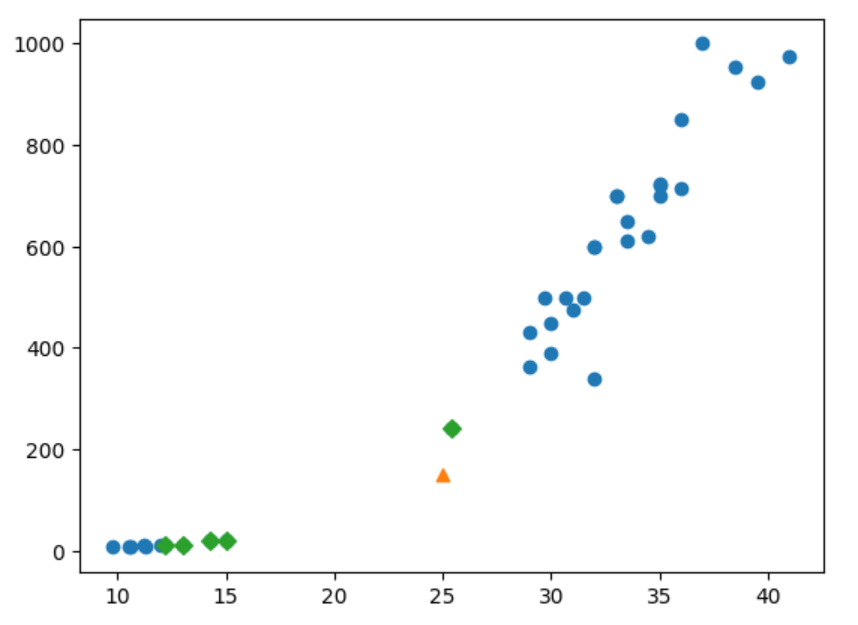
우리 생각과는 다르게 근접 데이터중 4개가 빙어임을 볼 수 있습니다.
여기서 오류는 x축과 y축의 스케일이 달라 발생한 오류입니다.
스케일 차이를 맞추는 방법 x축과 y축의 데이터 값을 표준점수로 표현하면 됩니다.
표준점수는 각 데이터가 0에서 표준편차의 몇배 만큼 떨어져 있는지를 나타냅니다. 표준점수는 (data - mean) / std 로 구할 수 있습니다
#스케일을 맞추기 위해 표준점수 이용
#평균과 표준편차 구하기
mean = np.mean(train_input, axis = 0) #axis = 0은 행을 따라 각 열의 통계 값을 계산합니다.
std = np.std(train_input, axis = 0)
#표준점수를 적용한 훈련 데이터 만들기
train_scaled = (train_input - mean) / std
#전처리 데이터를 시각화 및 모델 훈련
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.xlabel('length')
plt.ylabel('weight')
new = ([25, 150] - mean) / std
plt.scatter(new[0], new[1], marker = '^')
plt.show()
kn.fit(train_scaled, train_target)
test_scaled = (test_input - mean) / std
kn.score(test_scaled, test_target)
kn.predict([new])
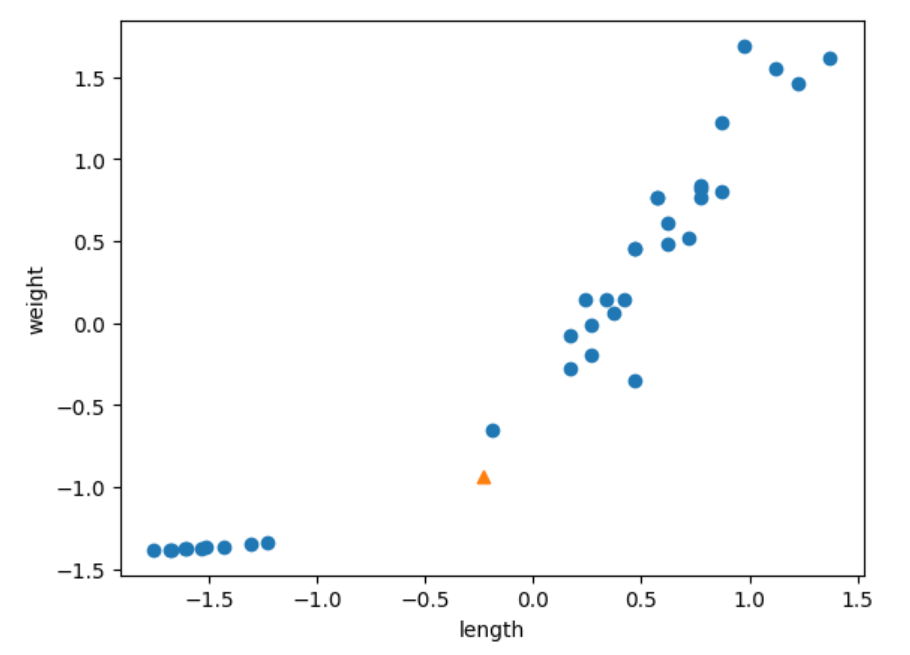
위 그래프는 표준점수를 이용해 데이터의 스케일을 조정해준 그래프 입니다.
이처럼 스케일을 조정후 데이터를 예측 시키면 올바르게 도미로 예측합니다.
#전처리 이후 최근접 객체 시각화
distances, indexes = kn.kneighbors([new])
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.xlabel('length')
plt.ylabel('weight')
plt.scatter(new[0], new[1], marker = '^')
plt.scatter(train_scaled[indexes,0], train_scaled[indexes,1], marker = 'D')
plt.show()
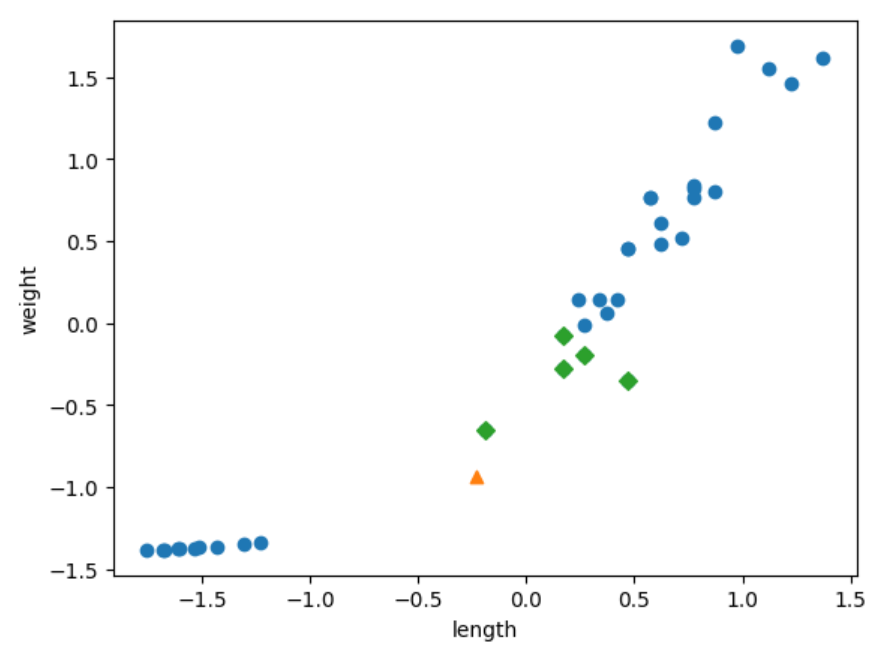
이번에는 근접 객체 5개중 5개가 모두 도미로 올바르게 계산이 진행되었습니다.
이상으로 포스팅을 마칩니다.